

AI & the environment
Blegging for some knowledge

In unpacking this new (but very old!) form of education, one of the things we need to do is get clear on how AI can help with it — if at all!
Imaginary Interlocutor: Did Kieran Egan write a lot about AI?
His books were written before LLMs came out, so no, not at all.
I.I.: Then why are we talking about this?
Egan pointed out that the ecstasy of learning comes when the deep meshy muck of information is brought out into the classroom, and begin to congeal in new ways inside people’s heads.
Usually, we talk about this in terms of how the information is structured. We say we need to return it from the academic-speak of PHILOSOPHIC (👩🔬) understanding back into the humans-everywhere speak of MYTHIC (🧙♂️) and ROMANTIC (🦹♂️) understanding. And this is true! When we’re able to do this, we revivify, revitalize, rehumanize, and re-enchant the content being learned.1
But the other side of this is that you want to have a LOT of information. In order for students to be infected with the love of physiology, or computer science, or math, or poetry, or whatever, they need to have gained a lot of knowledge about it.
Egan put it thusly:
The more you know about something, the more interesting it becomes... The person without the intellectual resources deep knowledge can provide is much more likely to be bored.
– Kieran Egan, Learning in Depth: A Simple Innovation That Can Transform Schooling
So in order to make it matter to themselves (and then to their students), teachers need to become mini-experts on what they’re teaching. Alas, contemporary teacher training is, let’s say, not so good at helping new teachers develop the deep intellectual resources about their subjects.
In the past, this has been a major limitation of how Egan education can spread.
But now we have LLMs — the large language models like ChatGPT, Claude, and so forth. I use them all the stinking time to gain knowledge of the things I’ll be teaching. What used to take hours of research now takes seconds. They are, warts and all, ludicrously efficient at delivering mostly-true information about abstruse topics.
But oh, there are warts.
I’d like your help. I’d like to take just one aspect of something people worry about with LLMs — their environmental impact — and see if what agreements we can, in the comments, come to.
I’d like to aim for two things:
what numbers can we agree on? (e.g. “using one normal LLM search takes x amount of electricity”)
how can we make contextual, human sense of those numbers? (e.g. “a half-hour of normal conversation with an AI takes __ as much energy as streaming TV”)
To help with this, I’d like to suggest a few things:
stay on topic — don’t talk about other AI issues (e.g. how accurate/inaccurate they are, fears of being paperclipped, effects on kids)
share where you’re getting your numbers from
don’t defame anyone else’s source (e.g. “well that person is a known climate-denier” or “once shoved a dog down a flight of stairs” or whatever) — provide what you think to be a better source
I’ll delete any posts that in my mind egregiously violate #1; if you’re on the border, I might ask you to edit it. Be over-the-top kind to people you disagree with. If it helps, put on a nice set of clothes before hitting “reply”.
Imaginary Interlocutor: Brandon, how do you stand on this?
Lightly. My starting point for this is Andy Masley’s recent post on this question:

I recommend starting with it, too. He responds to objections like “A ChatGPT prompt uses too much energy/water”, “ChatGPT is ten times as bad as a Google search”, “Data centers are an environmental disaster”, and much more! Here’s one of his diagrams that really hit home for me:
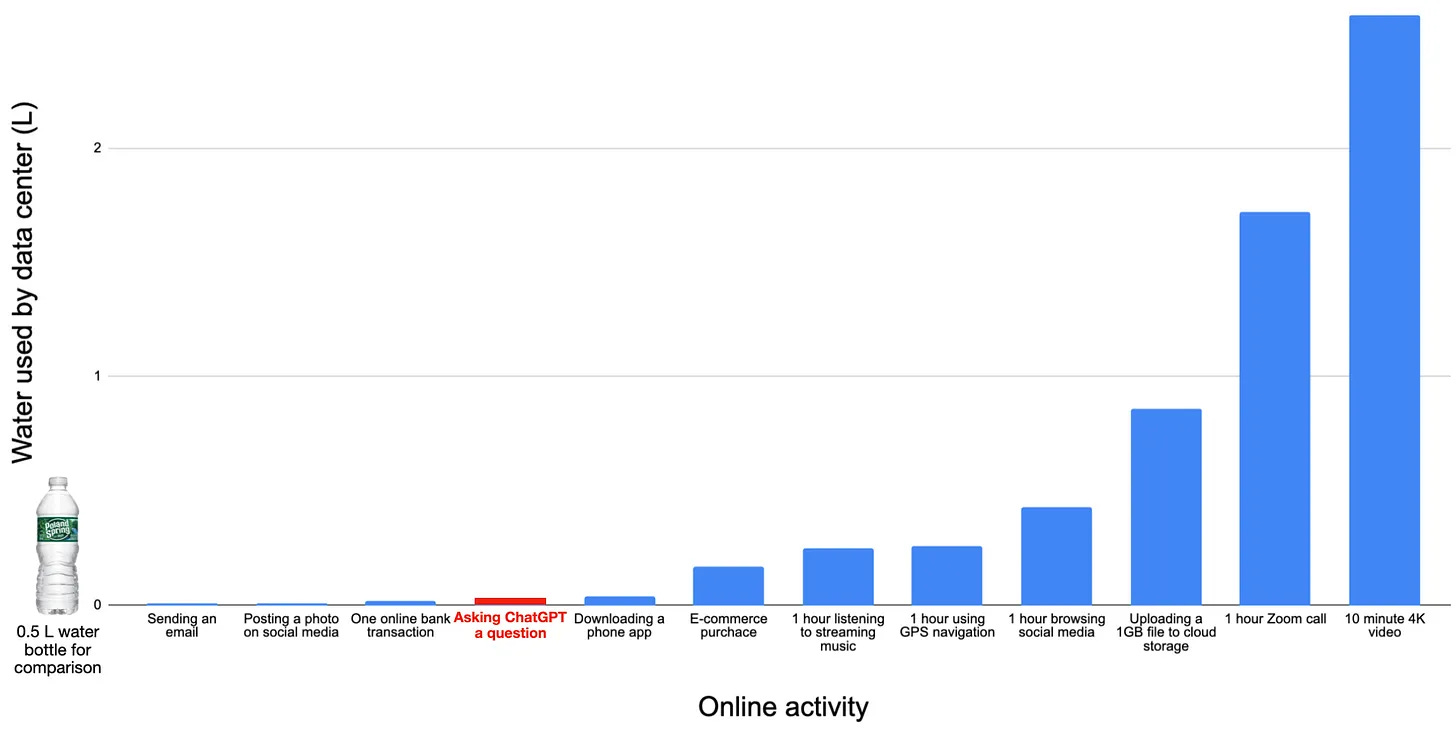
If you read it, you might also want to read his replies to the criticisms he got on his original longer piece — and then you might want to read his longer piece itself!
Where Masley’s piece is wrong, I want to change my mind on this. Where it’s right, I’d like to be confident of it, so I can be bold in helping teachers make use of these tools that can help us rehumanize education.
This is an experiment to see how well our emerging little community can do with a controversial (but still fact-based) question. I’ll try to call out my favorite responses by name — feel free to crown yourself in glory!
I’m focusing mostly on elementary & middle school education here. A mind full of pure, inhuman, abstractions actually sits close to the crowning achievement of Egan education — I tend to focus on the opposite because I’m trying to ward against the classic mistake of educational Traditionalism, which is to mistake that goal for the path itself.
Ooh! This is interesting. I still need to read his whole piece. I looked at the graph, and there in the middle is "asking chatGPT a question." Does he say how he came up with the data for this statistic? Because I was reading somewhere recently (and I wish I knew where) that being polite to AI is a huge waste of energy; adding three words to the beginning of a question "Would you please..." takes 50ml more water (was it really that much?) than leaving them off. So, tho he quantifies some other statistics with measurements, the question that is asked of chatGPT is unquantified.
In addition, his chart is in units of one. If comparing "asking chatGPT a question" to "10 min 4k video," there are simply a lot of differences in metrics. I mean, how many questions does this person ask chatGPT in 10 minutes? I can type fast! Shouldn't they be compared that way? And then there's the water usage of generative AI (asking for a composition) vs. simply asking for data. These require vastly different amounts of water, yet he doesn't quantify them in the chart.
But I'll search for that article I read that I thought had good quantitative measurements on water for input & output. Or maybe there's better information on it somewhere. I like reliable reference to primary resource for statistical data to enable me to check up on how others are using their statistics, so if that can be found, it would be awesome.
A back of the envelope calculation to give another estimate for the LLM consumption including training:
Lets assume the H100 gpu represents most of the AI companies' compute.
Each is 700 watt max TDP, so (x8760 hour in the year) 6 million watt hours per year. Times 2 millions H100 sold in 2024 worldwide --> 12000 gigawatt hour.
(The GPUs are used 100% all the time, either for inferring or for training new models).
OpenAI has 500 millions "users" (couldn't find good sources for those, but that number keeps coming up). It's pretty likely that most people using LLM must have made an openAI account at one point.
So 12000gigawatthour divided by 500million users of LLM so 24000watt hour per user.
That's about equal to running a kitchen oven for 15 hours. Which is much more than I expected, but is still negligable when compared to ordering on amazon, eating meat or driving a car.
LLM has plenty of problems, being bad for the environment isn't one of them (yet).
I'll consider limiting my LLM use (which i do enjoy) if we've considered stopping those much worse other things before.